01Communication-Efficient_Learning_of_Deep_Networks_from_Decentralized_Data
论文标题:《Communication-Efficient Learning of Deep Networks from Decentralized Data》,发表于AISTATS 2017
Abstract
We advocate an alternative that leaves the training data distributed on
the mobile devices, and learns a shared model by
aggregating locally-computed updates. We term
this decentralized approach Federated Learning
robust to the unbalanced and non-IID data distributions
Communication costs are the principal constraint, and
we show a reduction in required communication
rounds by 10–100× as compared to synchronized
stochastic gradient descent.
现代移动设备能够接触到大量适合用于训练模型的数据,以进一步优化用户使用此类设备的体验,如语音识别、文字输入和图片选择等。但是这些数据一般是敏感的私人数据或是海量数据,不适合使用传统方法训练,因此作者提出一种基于分布式训练并共享聚合模型的训练方法,并命名为联邦学习(Fedrated Learning)
Introduction
amount of data, much of it private in nature
the sensitive nature of the data means there are risks and responsibilities to storing it in a centralized location.
only this update is communicated ,limiting the
attack surface to only the device, rather than the device and
the cloud.
作者研究了一种允许用户们通过自己的高价值数据获得并共享更好的模型,但无需数据共享,并命名为联邦学习技术(因为模型学习目标是通过一个中央Server管理一个由参与模型学习的设备组成的松散联邦)。各个用户通过本地数据集训练本地模型,并将update发送到Server。整个联邦学习过程中,只有用户发送的update参与了communication,并且由于这些update只是针对当前的模型,应用后就没有任何必要存储他们了,在一定程度上确保了用户私人数据的安全。
联邦学习技术的重要优势在于分离了模型训练过程中对训练数据的直接访问,并通过限制攻击面极大程度上降低了隐私和安全风险
Contributions如下:
确认将分离式移动设备训练问题作为研究方向。
对可应用于联邦学习思想技术的算法选择。
引入了FederatedAveraging算法,该算法结合了每个客户端上的随机梯度下降和执行模型平均的服务器。通过实验显示了该算法对不平衡和非独立同分布数据的鲁棒性,并能减少在分布式数据上训练深度网络所需要的通信次数
Our primary contributions are 1) the identification of the
problem of training on decentralized data from mobile devices as an important research direction; 2) the selection of
a straightforward and practical algorithm that can be applied
to this setting; and 3) an extensive empirical evaluation of
the proposed approach. More concretely, we introduce the
FederatedAveraging algorithm, which combines local stochastic gradient descent (SGD) on each client with
a server that performs model averaging. We perform extensive experiments on this algorithm, demonstrating it is
robust to unbalanced and non-IID data distributions, and
can reduce the rounds of communication needed to train a
deep network on decentralized data by orders of magnitude
联邦学习的特点
数据大都来自于真实数据训练效果更加贴合实际;
数据高度敏感且相对于单个用户来说,数据量非常大;
对于有监督学习,可以通过与用户的互动轻松对数据进行标号。
联邦学习对于隐私性的保护
会进行通信的数据只有需要的更新,这保证了用户数据的安全;
更新数据不需要保存,一旦更新成功,更新数据将被丢失;
通过更新数据对原始数据的破解几乎不可能。
联邦学习与分布式学习有着几个显著的不同
数据分布非独立同分布:不同的用户有着不同的行为;
数据分布不平衡:指某些参与者的数据可能很多,而某些参与者数据可能很少;
大量的参与者:一个软件的用户可能非常多(例如某款输入法);
受限的通信:参与者的信号可能非常差,甚至出现离线的情况;
联邦学习需要处理以下问题
各个参与方的数据可能会发生改变(例如删除、添加、编辑照片);
参与方的数据分布非常复杂(不同的群体的手机使用情况差异可能会非常大
联邦学习与传统数据中心计算的不同
传统的数据中心计算,往往通信的消耗是相对较小的,计算的时间是相对较大的,联邦学习正好相反(用户可能只会在特定的时间才回进行上传,例如睡觉时,而由于用户的处理器往往不会太差,计算的耗费相对就会较小)
有两种方法能够缓解联邦学习中通信耗时的问题(核心都是让用户进行大量的计算,这样能减少通信时间的占比):
增加并行度,让更多的参与者进行计算;
增加计算度,让一个参与者进行更多的计算。
相关工作介绍
传统的分布式学习考虑的是平衡的分布(各个参与方的计算量与各自的计算能力相匹配)和独立同分布(各方的数据是独立同分布的);
传统的分布式学习只会进行一次集中更新,已经被证明,这样训练出来的模型在最坏情况下可能会比在单个参与方训练的模型效果差。
The FederatedAveraging Algorithm

计算量由三个关键参数控制:C,在每轮上执行计算的客户端的比例;E,每个客户端在每轮上对其本地数据集进行的训练通过数;B,客户端更新所使用的本地小批量大小。我们写入B=∞以指示将整个本地数据集作为单个小批处理,取B=∞和E=1,它正好对应于FedSGD。
B=∞: 代表minibatch=用户本地全部数据
B=∞ & E = 1: FedAvg 等价于 FedSGD
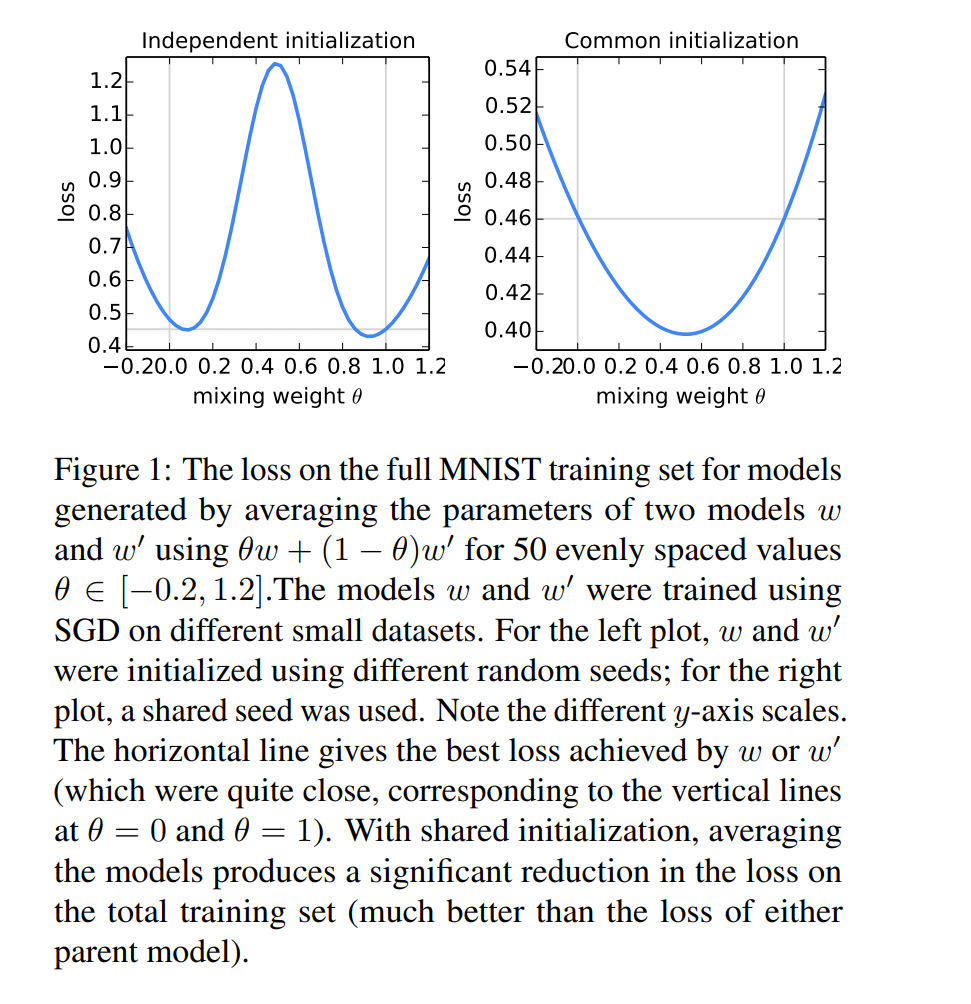
Experimental Results
查看https://blog.csdn.net/qq_45523675/article/details/127899784,他写的很详细很不错
Conclusions and Future Work
Our experiments show that federated learning can be made
practical, as FedAvg trains high-quality models using relatively few rounds of communication, as demonstrated by
results on a variety of model architectures: a multi-layer
perceptron, two different convolutional NNs, a two-layer
character LSTM, and a large-scale word-level LSTM.
While federated learning offers many practical privacy benefits, providing stronger guarantees via differential privacy [14, 13, 1], secure multi-party computation [18], or
their combination is an interesting direction for future work.
Note that both classes of techniques apply most naturally to
synchronous algorithms like FedAvg.
各种模型架构(多层感知器,两种不同的卷积神经网络, 两层字符LSTM和大规模词级LSTM)的实验结果表明:当FedAvg使用相对较少的交流轮次来训练高质量的模型时,联邦学习是实际可行的。
尽管联合学习提供了许多实用的隐私优势,但通过差分隐私、多方安全计算或者它们的组合提供更强的隐私保证是未来工作的有趣方向
参考文章链接
https://blog.csdn.net/qq_45523675/article/details/127899784
https://zhuanlan.zhihu.com/p/656686796
https://zhuanlan.zhihu.com/p/445458807