lecture3-cs231n
“Neural Network” is a very broad term; these are more accurately called
“fully-connected networks” or sometimes “multi-layer perceptrons” (MLP)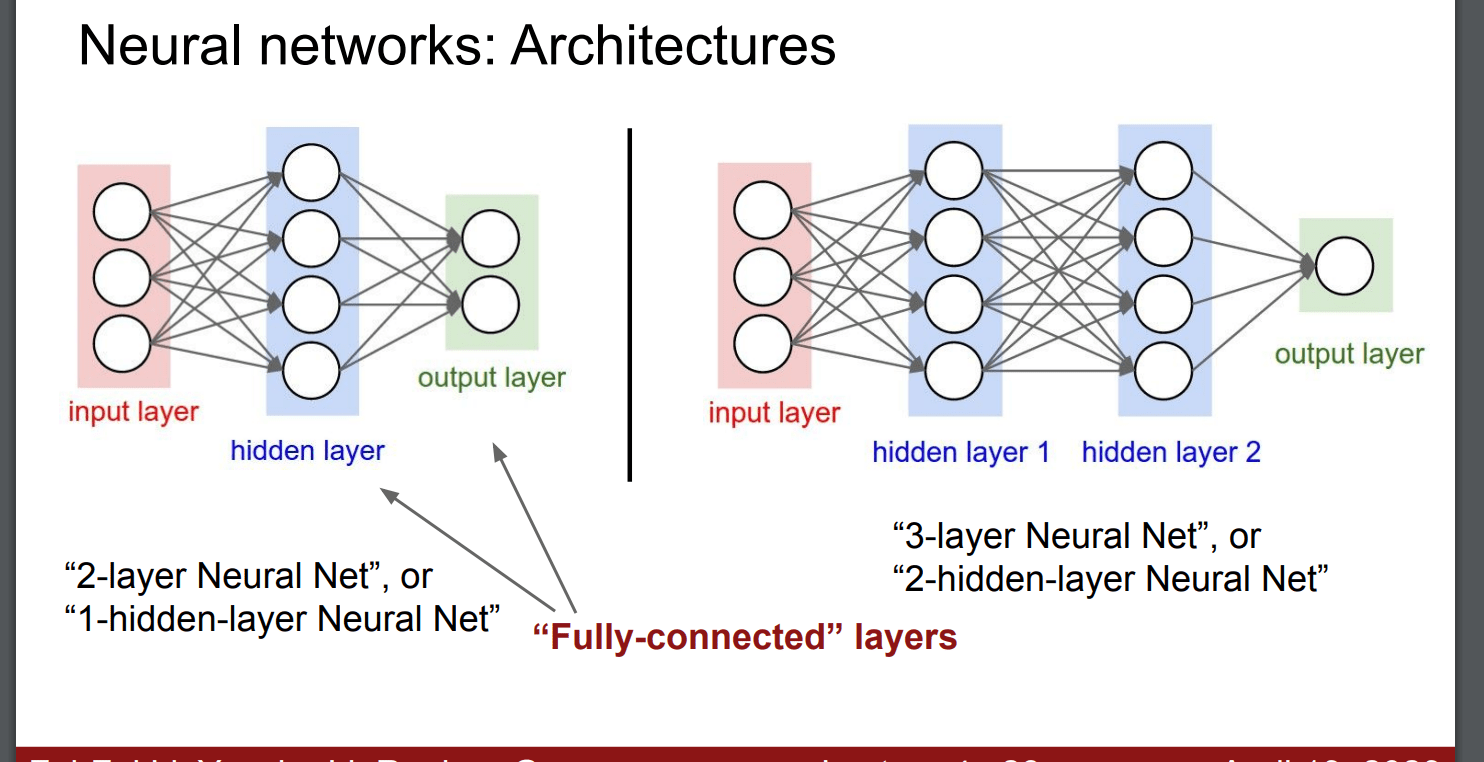
函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度
Backpropagation
反向传播是利用链式法则递归计算表达式的梯度的方法。理解反向传播过程及其精妙之处,对于理解、实现、设计和调试神经网络非常关键。
反向传播是一个优美的局部过程。在整个计算线路图中,每个门单元都会得到一些输入并立即计算两个东西:1. 这个门的输出值,和2.其输出值关于输入值的局部梯度。门单元完成这两件事是完全独立的,它不需要知道计算线路中的其他细节。然而,一旦前向传播完毕,在反向传播的过程中,门单元门将最终获得整个网络的最终输出值在自己的输出值上的梯度。链式法则指出,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。
激活函数
用于非线性数据经过层层激活函数可以变为线性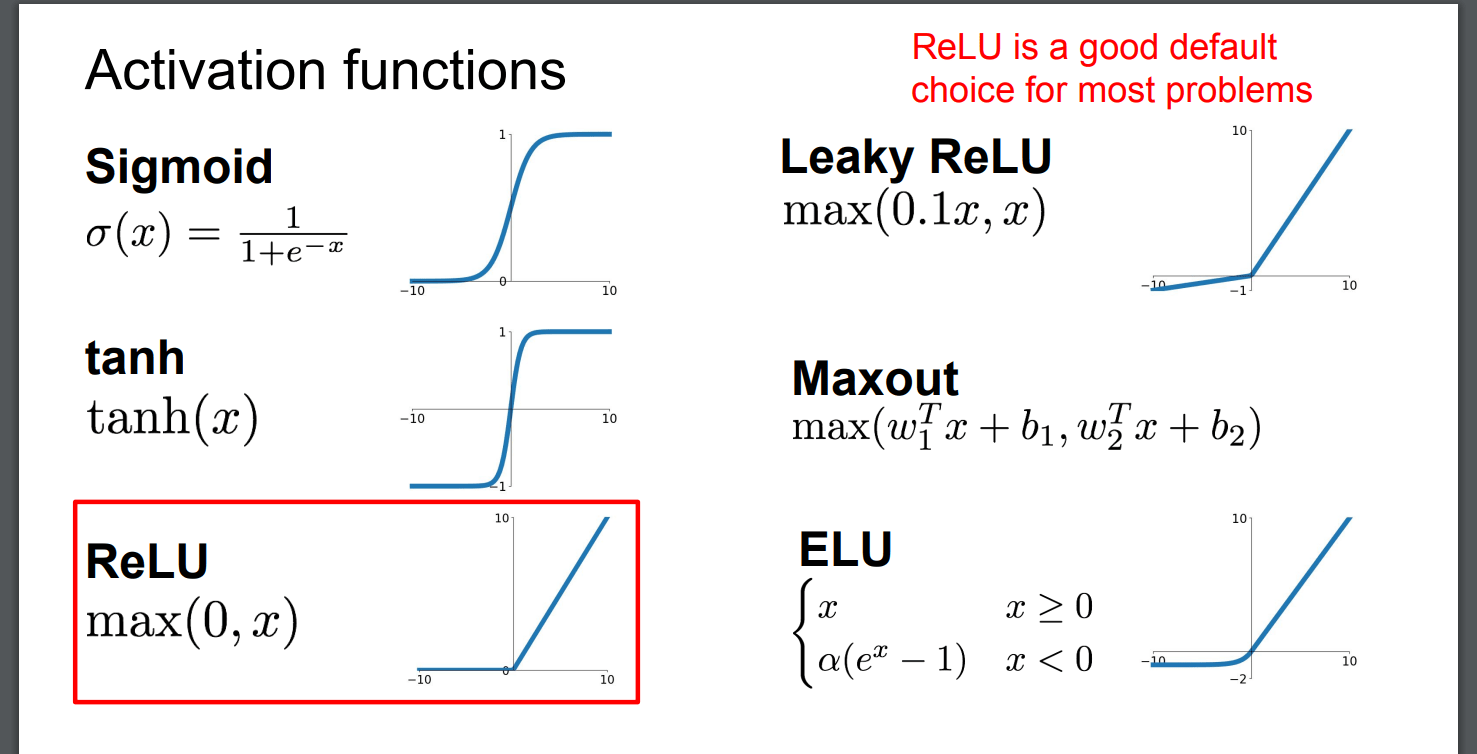
用向量化操作计算梯度

上述内容考虑的都是单个变量情况,但是所有概念都适用于矩阵和向量操作。然而,在操作的时候要注意关注维度和转置操作。
矩阵相乘的梯度:可能最有技巧的操作是矩阵相乘(也适用于矩阵和向量,向量和向量相乘)的乘法操作
提示:要分析维度! 注意不需要去记忆dW和dX的表达,因为它们很容易通过维度推导出来。例如,权重的梯度dW的尺寸肯定和权重矩阵W的尺寸是一样的,而这又是由X和dD的矩阵乘法决定的(在上面的例子中X和W都是数字不是矩阵)。总有一个方式是能够让维度之间能够对的上的。例如,X的尺寸是[10x3],dD的尺寸是[5x3],如果你想要dW和W的尺寸是[5x10],那就要dD.dot(X.T)。
小结
对梯度的含义有了直观理解,知道了梯度是如何在网络中反向传播的,知道了它们是如何与网络的不同部分通信并控制其升高或者降低,并使得最终输出值更高的。
讨论了分段计算在反向传播的实现中的重要性。应该将函数分成不同的模块,这样计算局部梯度相对容易,然后基于链式法则将其“链”起来。重要的是,不需要把这些表达式写在纸上然后演算它的完整求导公式,因为实际上并不需要关于输入变量的梯度的数学公式。只需要将表达式分成不同的可以求导的模块(模块可以是矩阵向量的乘法操作,或者取最大值操作,或者加法操作等),然后在反向传播中一步一步地计算梯度。