lecture1-cs231n
overview


data_drive
Image Classification
A Core Task in Computer Vision
Today:
● The image classification task
● Two basic data-driven approaches to image classification
○ K-nearest neighbor and linear classifier
/*
An image is a tensor of integers
between [0, 255]:
e.g. 800 x 600 x 3
(3 channels RGB)
*/
直接根绝分类对象写算法判断几乎不可能
干扰:
Illumination 光线
Background Clutter 背景混乱
Occlusion 只露出一部分
Deformation 会形变
······
no obvious way to hard-code the algorithm for
recognizing a cat, or other classes.
Machine Learning: Data-Driven Approach
- Collect a dataset of images and labels
- Use Machine Learning algorithms to train a classifier
- Evaluate the classifier on new images
Knn K Nearest Neighbor Classifier(最近邻分类器)
KNN就是记忆存储大量得训练集,然后每次测试时候根据距离判断与测试图片最相似得K张照片,再根据投票选择最合适lable
(即矩阵差值最小的K个)
1 | |
两种距离: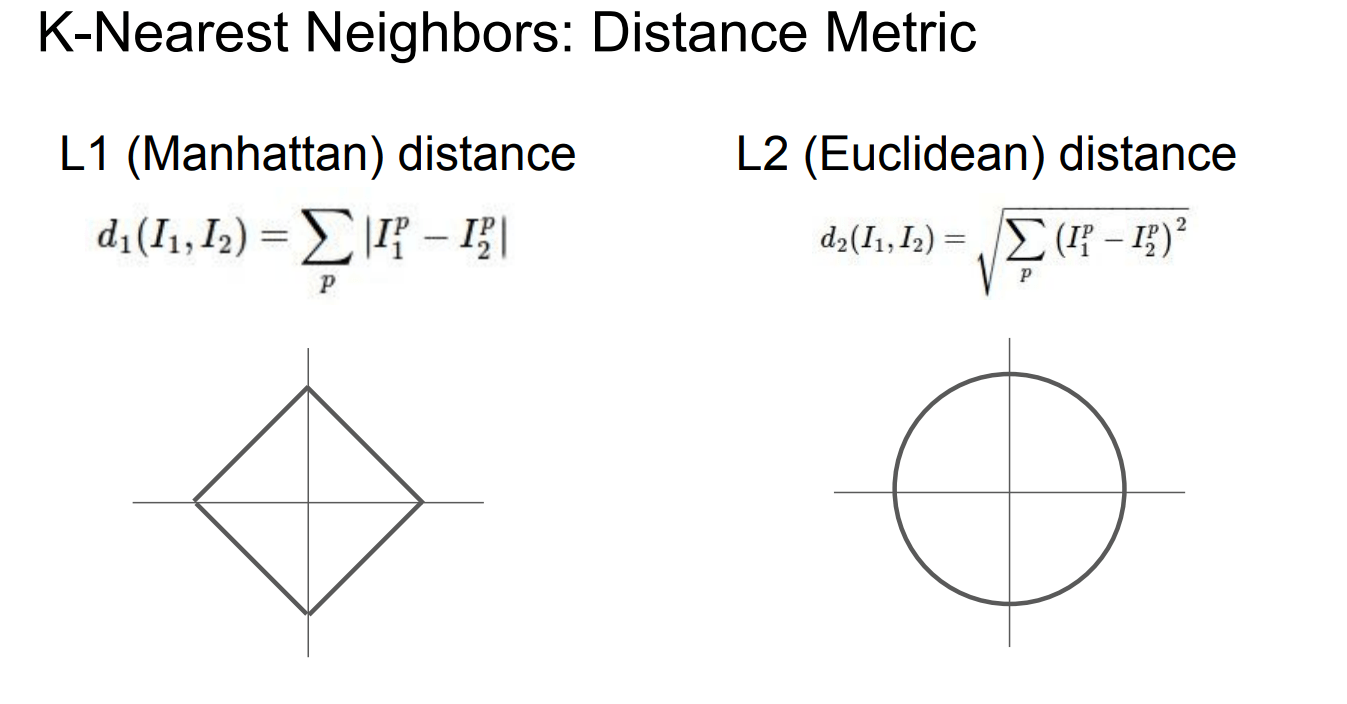
超参数:得提前设置好
Hyperparameters
两个选择问题:
What is the best value of k to use?
What is the best distance to use?
These are hyperparameters: choices about
the algorithms themselves.
Very problem/dataset-dependent.
Must try them all out and see what works best.
k-NN分类器需要设定k值,那么选择哪个k值最合适的呢?我们可以选择不同的距离函数,比如L1范数和L2范数等,那么选哪个好?还有不少选择我们甚至连考虑都没有考虑到(比如:点积)。所有这些选择,被称为超参数(hyperparameter)。在基于数据进行学习的机器学习算法设计中,超参数是很常见的。一般说来,这些超参数具体怎么设置或取值并不是显而易见的。
训练集、验证集、测试集
(Example Dataset: CIFAR10
10 classes
50,000 training images
10,000 testing images)
1 | |
K-Nearest Neighbors: Summary
In image classification we start with a training set of images and labels, and
must predict labels on the test set
The K-Nearest Neighbors classifier predicts labels based on the K nearest
training examples
Distance metric and K are hyperparameters
Choose hyperparameters using the validation set
Only run on the test set once at the very end!
小结:
介绍了图像分类问题。在该问题中,给出一个由被标注了分类标签的图像组成的集合,要求算法能预测没有标签的图像的分类标签,并根据算法预测准确率进行评价。
介绍了一个简单的图像分类器:最近邻分类器(Nearest Neighbor classifier)。分类器中存在不同的超参数(比如k值或距离类型的选取),要想选取好的超参数不是一件轻而易举的事。
选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好那个。
如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力。
最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体分身。
在接下来的课程中,我们将专注于解决这些问题和挑战,并最终能够得到超过90%准确率的解决方案。该方案能够在完成学习就丢掉训练集,并在一毫秒之内就完成一张图片的分类
Linear Classifier
f(x,W) = Wx + b
计算根据w,b选择分数最高的,即为该标签(w是向量)
1.代数表示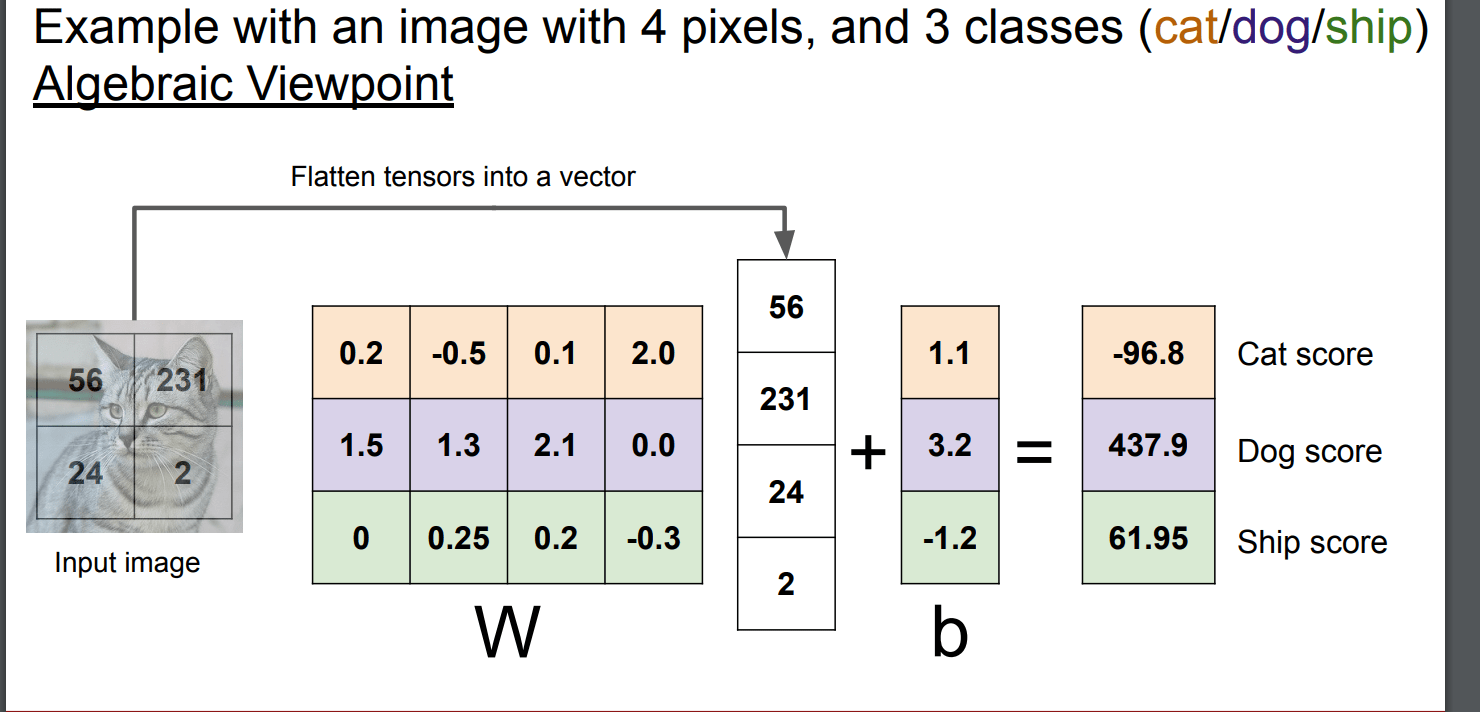
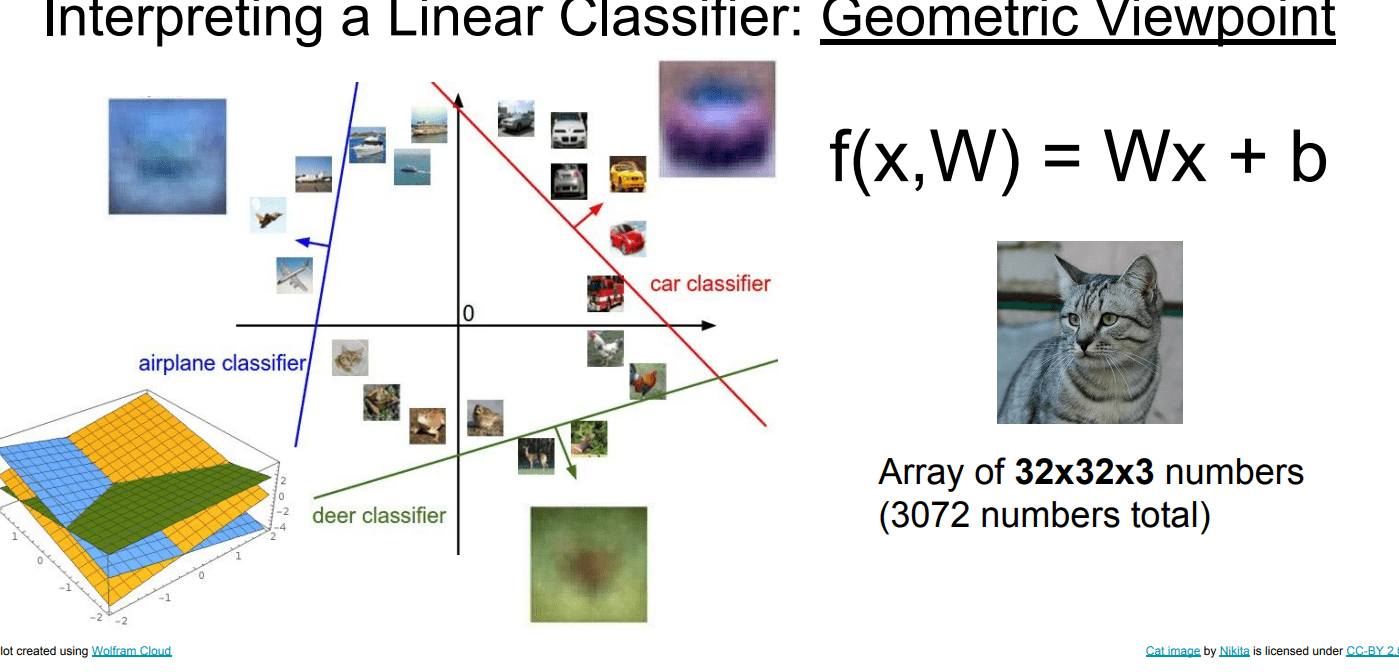
2.可视化表示
即用最合适得参数W和b改为矩阵表示
3.线性表示